Dynamic Persistent Volumes with CSE Kubernetes and Ceph
Introduction
Application containerization with Docker is fast becoming the default deployment pattern for many business applications and Kubernetes (k8s) the method of managing these workloads. While containers generally should be stateless and ephemeral (able to be deployed, scaled and deleted at will) almost all business applications require data persistence of some form. In some cases it is appropriate to offload this to an external system (a database, file store or object store in public cloud environments are common for example).
This doesn’t cover all storage requirements though, and if you are running k8s in your own environment or in a hosted service provider environment you may not have access to compatible or appropriate storage. One solution for this is to build a storage platform alongside a Kubernetes cluster which can provide storage persistence while operating in a similar deployment pattern to the k8s cluster itself (scalable, clustered, highly available and no single points of failure).
VMware Container Service Extension (CSE) for vCloud Director (vCD) is an automated way for customers of vCloud powered service providers to easily deploy, scale and manage k8s clusters, however CSE currently only provides a limited storage option (an NFS storage server added to the cluster) and k8s persistent volumes (PVs) have to be pre-provisioned in NFS and assigned to containers/pods rather than being generated on-demand. This can also cause availability, scale and performance issues caused by the pod storage being located on a single server VM.
There is certainly no ‘right’ answer to the question of persistent storage for k8s clusters – often the choice will be driven by what is available in the platform you are deploying to and the security, availability and performance requirements for this storage.
In this post I will detail a deployment using a ceph storage cluster to provide a highly available and scalable storage platform and the configuration required to enable a CSE deployed k8s cluster to use dynamic persistent volumes (DPVs) in this environment.
Due to the large number of servers/VMs involved, and the possibility of confusion / working on the wrong server console - I've added buttons like this  prior to each section to show which system(s) the commands should be used on.
prior to each section to show which system(s) the commands should be used on.
I am not an expert in Kubernetes or ceph and have figured out most of the contents in this post from documentation, forums, google and (sometimes) trial and error. Refer to the documentation and support resources at the links at the end of this post if you need the ‘proper’ documentation on these components. Please do not use anything shown in this post in a production environment without appropriate due diligence and making sure you understand what you are doing (and why!).
With that out of the way - on with the configuration...
Solution Overview
Our solution is going to be based on a minimal viable installation of ceph with a CSE cluster consisting of 4 ceph nodes (1 admin and 3 combined OSD/mon/mgr nodes) and a 4 node Kubernetes cluster (1 master and 3 worker nodes). There is no requirement for the OS in the ceph cluster and the kubernetes cluster to be the same, however it does make it easier if the packages used for ceph are at the same version which is easier to achieve using the same base OS for both clusters. Since CSE currently only has templates for Ubuntu 16.04 and Photon OS, and due to the lack of packages for the ‘mimic’ release of ceph on Photon OS, this example will use Ubuntu 16.04 LTS as the base OS for all servers.
The diagram below shows the components required to be deployed – in the lab environment I’m using the DNS and NTP servers already exist: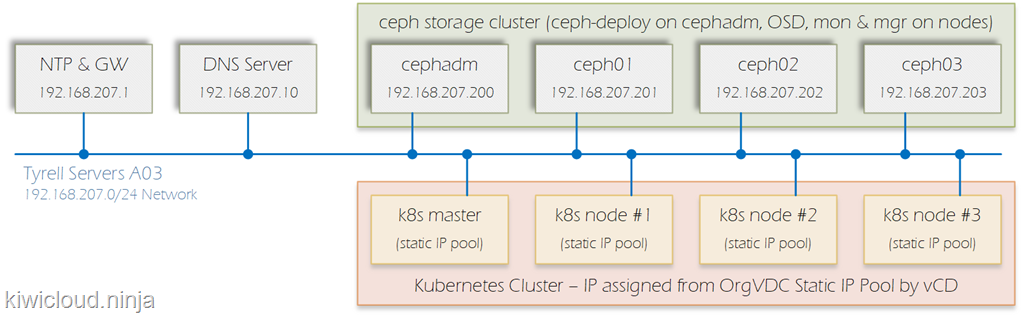
In production ceph clusters, the monitor (mon) service should run on separate machines from the nodes providing storage (OSD nodes), but for a test/dev environment there is no issue running both services on the same nodes.
Pre-requisites
You should ensure that you have the following enabled and configured in your environment before proceeding:
| Configuration Item | Requirement |
|---|---|
| DNS | Have a DNS server available and add host (‘A’) records for each of the ceph servers. Alternatively it should be possible to add /etc/hosts records on each node to avoid the need to configure DNS. Note that this is only required for the ceph nodes to talk to each other, the kubernetes cluster uses direct IP addresses to contact the ceph cluster. |
| NTP | Have an available NTP time source on your network, or access to external ntp servers |
| Static IP Pool | Container Service Extension (CSE) requires a vCloud OrgVDC network with sufficient addresses available from a static IP pool for the number of kubernetes nodes being deployed |
| SSH Key Pair | Generated SSH key pair to be used to administer the deployed CSE servers. This could (optionally) also be used to administer the ceph servers |
| VDC Capacity | Ensure you have sufficient resources (Memory, CPU, Storage and number of VMs) in your vCD VDC to support the desired cluster sizes |
Ceph Storage Cluster
The process below describes installing and configuring a ceph cluster on virtualised hardware. If you have an existing ceph cluster available or are building on physical hardware it's best to follow the ceph official documentation at this link for your circumstances.
Ceph Server Builds
The 4 ceph servers can be built using any available hardware or virtualisation platform, in this exercise I’ve built them from an Ubuntu 16.04 LTS server template with 2 vCPUs and 4GB RAM for each in the same vCloud Director environment which will be used for deployment of the CSE kubernetes cluster. There are no special requirements for installing/configuring the base Operating System for the ceph cluster. If you are using a different Linux distribution then check the ceph documentation for the appropriate steps for your distribution.
On the 3 storage nodes (ceph01, ceph02 and ceph03) add a hard disk to the server which will act as the storage for the ceph Object Storage Daemon (OSD) – the storage pool which will eventually be useable in Kubernetes. In this example I’ve added a 50GB disk to each of these VMs.
Once the servers are deployed the following are performed on each server to update their repositories and upgrade any modules to current security levels. We will also upgrade the Linux kernel to a more up-to-date version by enabling the Ubuntu Hardware Extension (HWE) kernel which resolves some compatibility issues between ceph and older Linux kernel versions.
1$ sudo apt-get update
2$ sudo apt-get upgrade
3$ sudo apt-get install --install-recommends linux-generic-hwe-16.04 -y
Each server should now be restarted to ensure the new Linux kernel is loaded and any added storage disks are recognised.
Ceph Admin Account
We need a user account configured on each of the ceph servers to allow ceph-deploy to work and to co-ordinate access, this account must NOT be named 'ceph' due to potential conflicts in the ceph-deploy scripts, but can be called just about anything else. In this lab environment I've used 'cephadmin'. First we create the account on each server and set the password, the 3rd line permits the cephadmin user to use 'sudo' without a password which is required for the ceph-deploy script:
1$ sudo useradd -d /home/cephadmin -m cephadmin -s /bin/bash
2$ sudo passwd cephadmin
3$ echo "cephadmin ALL = (root) NOPASSWD:ALL" > /etc/sudoers.d/cephadmin
From now on, (unless specified) use the new cephadmin login to perform each step. Next we need to generate an SSH key pair for the ceph admin user and copy this to the authorized-keys file on each of the ceph nodes.
Execute the following on the ceph admin node (as cephadmin):

1$ ssh-keygen -t rsa
Accept the default path (/home/cephadmin/.ssh/id_rsa) and don't set a key passphrase. You should copy the generated .ssh/id_rsa (private key) file to your admin workstation so you can use it to authenticate to the ceph servers.
Next, enable password logins (temporarily) on the storage nodes (ceph01,2 & 3) by running the following on each node:

1$ sudo sed -i "s/.*PasswordAuthentication.*/PasswordAuthentication yes/g" /etc/ssh/sshd_config
2$ sudo systemctl restart sshd
Now copy the cephadmin public key to each of the other ceph nodes by running the following (again only on the admin node):
1$ ssh-keyscan -t rsa ceph01 >> ~/.ssh/known_hosts
2$ ssh-keyscan -t rsa ceph02 >> ~/.ssh/known_hosts
3$ ssh-keyscan -t rsa ceph03 >> ~/.ssh/known_hosts
4$ ssh-copy-id cephadmin@ceph01
5$ ssh-copy-id cephadmin@ceph02
6$ ssh-copy-id cephadmin@ceph03
You should now confirm you can ssh to each storage node as the cephadmin user from the admin node without being prompted for a password:
1$ ssh cephadmin@ceph01 sudo hostname
2ceph01
3$ ssh cephadmin@ceph02 sudo hostname
4ceph02
5$ ssh cephadmin@ceph03 sudo hostname
6ceph03
If everything is working correctly then each command will return the appropriate hostname for each storage node without any password prompts.
Optional: It is now safe to re-disable password authentication on the ceph servers if required (since public key authentication will be used from now on) by:
1$ sudo sed -i "s/.*PasswordAuthentication.*/PasswordAuthentication no/g" /etc/ssh/sshd_config
2$ sudo systemctl restart sshd
You'll need to resolve any authentication issues before proceeding as the ceph-deploy script relies on being able to obtain sudo-level remote access to all of the storage nodes to install ceph successfully.
You should also at this stage confirm that you have time synchronised to an external source on each ceph node so that the server clocks agree, by default on Ubuntu 16.04 timesyncd is configured automatically so nothing needs to be done here in our case. You can check this on Ubuntu 16.04 by running timedatectl:
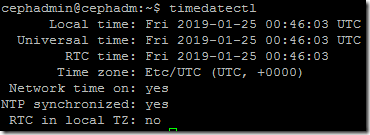
For some Linux distributions you may need to create firewall rules at this stage for ceph to function, generally port 6789/tcp (for mon) and the range 6800 to 7300 tcp (for OSD communication) need to be open between the cluster nodes. The default firewall settings in Ubuntu 16.04 allow all network traffic so this is not required (however, do not use this in a production environment without configuring appropriate firewalling).
Ceph Installation
On all nodes and signed-in as the cephadmin user (important!)
Add the release key:
1$ wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
Add ceph packages to your repository:
1$ echo deb https://download.ceph.com/debian-mimic/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
On the admin node only, update and install ceph-deploy:
1$ sudo apt update; sudo apt install ceph-deploy -y
On all nodes, update and install ceph-common:
```bash
$ sudo apt update; sudo apt install ceph-common -y
```Installing ceph-common on the storage nodes isn't strictly required as the ceph-deploy script can do this during cluster initiation, but pre-installing it in this way pulls in several dependencies (e.g. python v2 and associated modules) which can prevent ceph-deploy from running if not present so it is easier to do this way.
Next again working on the admin node logged in as cephadmin, make a directory to store the ceph cluster configuration files and change to that directory. Note that ceph-deploy will use and write files to the current directory so make sure you are in this folder whenever making changes to the ceph configuration.
1$ sudo apt install ceph-deploy -y
Now we can create the initial ceph cluster from the admin node, use ceph-deploy with the 'new' switch and supply the monitor nodes (in our case all 3 nodes will be both monitors and OSD nodes). Make sure you do NOT use sudo for this command and only run on the admin node:
1$ ceph-deploy new ceph01 ceph02 ceph03
If everything has run correctly you'll see output similar to the following: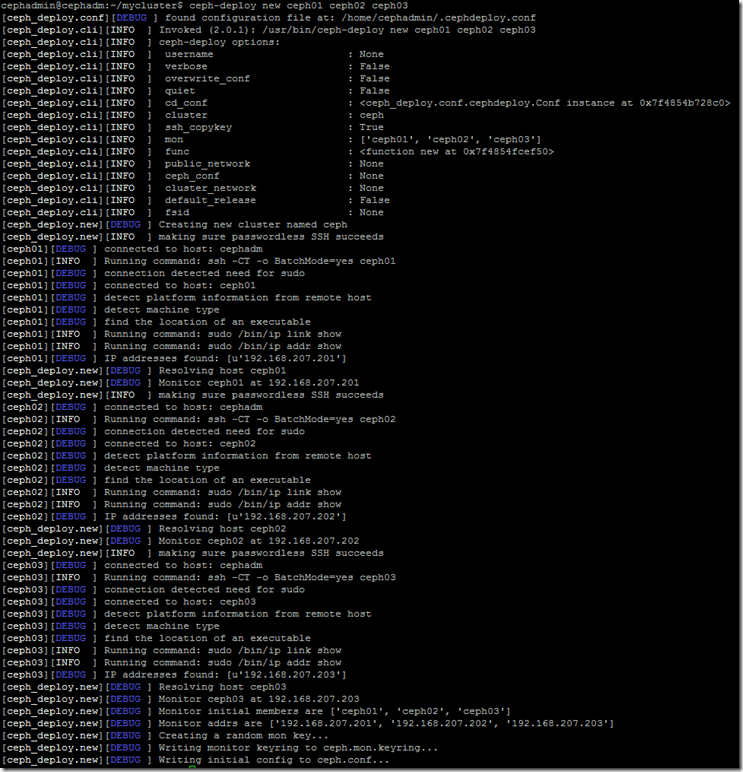
Checking the contents of the ~/mycluster/ folder should show the cluster configuration files have been added:
1$ ls -al ~/mycluster
2total 24
3drwxrwxr-x 2 cephadmin cephadmin 4096 Jan 25 01:03 .
4drwxr-xr-x 5 cephadmin cephadmin 4096 Jan 25 00:57 ..
5-rw-rw-r-- 1 cephadmin cephadmin 247 Jan 25 01:03 ceph.conf
6-rw-rw-r-- 1 cephadmin cephadmin 7468 Jan 25 01:03 ceph-deploy-ceph.log
7-rw------- 1 cephadmin cephadmin 73 Jan 25 01:03 ceph.mon.keyring
The ceph.conf file will look something like this:
1$ cat ~/mycluster/ceph.conf
2fsid = 98ca274e-f79b-4092-898a-c12f4ed04544
3mon_initial_members = ceph01, ceph02, ceph03
4mon_host = 192.168.207.201,192.168.207.202,192.168.207.203
5auth_cluster_required = cephx
6auth_service_required = cephx
7auth_client_required = cephx
Run the ceph installation for the nodes (again from the admin node only):
1$ ceph-deploy install ceph01 ceph02 ceph03
This will run through the installation of ceph and pre-requisite packages on each node, you can check the ceph-deploy-ceph.log file after deployment for any issues or errors.
Ceph Configuration
Once you've successfully installed ceph on each node, use the following (again from only the admin node) to deploy the initial ceph monitor services:
1$ ceph-deploy mon create-initial
If all goes well you'll get some messages at the completion of this process showing the keyring files being stored in your 'mycluster' folder, you can check these exist:
1$ ls -al ~/mycluster
2total 168
3drwxrwxr-x 2 cephadmin cephadmin 4096 Jan 25 01:17 .
4drwxr-xr-x 5 cephadmin cephadmin 4096 Jan 25 00:57 ..
5-rw------- 1 cephadmin cephadmin 113 Jan 25 01:17 ceph.bootstrap-mds.keyring
6-rw------- 1 cephadmin cephadmin 113 Jan 25 01:17 ceph.bootstrap-mgr.keyring
7-rw------- 1 cephadmin cephadmin 113 Jan 25 01:17 ceph.bootstrap-osd.keyring
8-rw------- 1 cephadmin cephadmin 113 Jan 25 01:17 ceph.bootstrap-rgw.keyring
9-rw------- 1 cephadmin cephadmin 151 Jan 25 01:17 ceph.client.admin.keyring
10-rw-rw-r-- 1 cephadmin cephadmin 247 Jan 25 01:03 ceph.conf
11-rw-rw-r-- 1 cephadmin cephadmin 128136 Jan 25 01:17 ceph-deploy-ceph.log
12-rw------- 1 cephadmin cephadmin 73 Jan 25 01:03 ceph.mon.keyring
To avoid having to specify the monitor node address and ceph.client.admin.keyring path in every command, we can now deploy these to each node so they are available automatically. Again working from the 'mycluster' folder on the admin node:
1$ ceph-deploy admin cephadmin ceph01 ceph02 ceph03
This should give the following: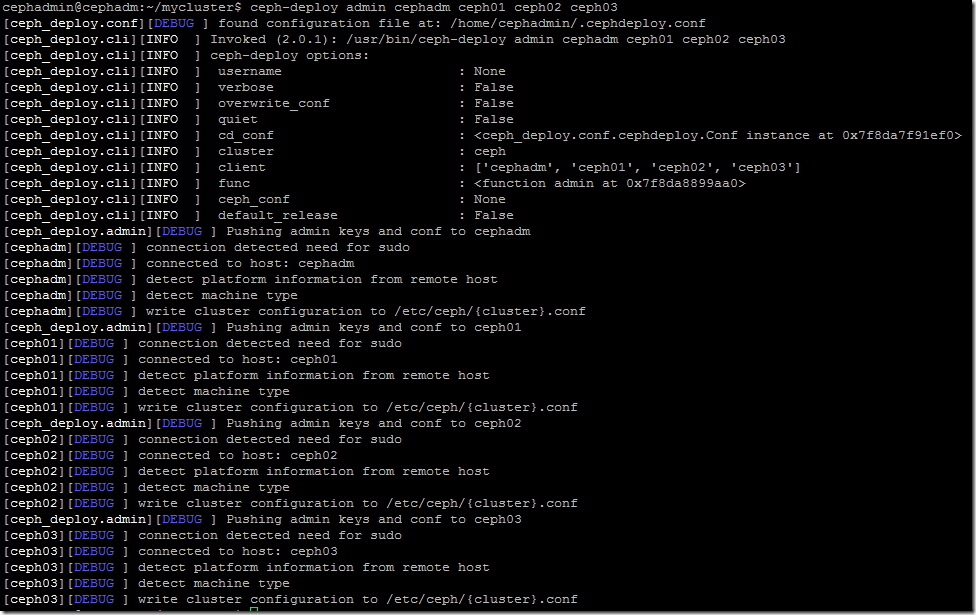
Next we need to deploy the manager ('mgr') service to the OSD nodes, again working from the 'mycluster' folder on the admin node:
1$ ceph-deploy mgr create ceph01 ceph02 ceph03
At this stage we can check that all of the mon and mgr services are started and ok by running (on the admin node):
1$ sudo ceph -s
2 cluster:
3 id: 98ca274e-f79b-4092-898a-c12f4ed04544
4 health: HEALTH_OK
5
6 services:
7 mon: 3 daemons, quorum ceph01,ceph02,ceph03
8 mgr: ceph01(active), standbys: ceph02, ceph03
9 osd: 0 osds: 0 up, 0 in
10
11 data:
12 pools: 0 pools, 0 pgs
13 objects: 0 objects, 0 B
14 usage: 0 B used, 0 B / 0 B avail
15 pgs:
As you can see, the manager ('mgr') service is installed on all 3 nodes but only active on the first and in standby mode on the other 2 - this is normal and correct. The monitor ('mon') service is running on all of the storage nodes.
Next we can configure the disks attached to our storage nodes for use by ceph. Ensure that you know and use the correct identifier for your disk devices (in this case, we are using the 2nd SCSI disk attached to the storage node VMs which is at /dev/sdb so that's what we'll use in the commands below). As before, run the following only on the admin node:
1$ ceph-deploy osd create --data /dev/sdb ceph01
2$ ceph-deploy osd create --data /dev/sdb ceph02
3$ ceph-deploy osd create --data /dev/sdb ceph03
For each command the last line of the logs shown when run should be similar to 'Host ceph01 is now ready for osd use.'
We can now check the overall cluster health with:
1$ ssh ceph01 sudo ceph health
2HEALTH_OK
3$ ssh ceph01 sudo ceph -s
4 cluster:
5 id: 98ca274e-f79b-4092-898a-c12f4ed04544
6 health: HEALTH_OK
7
8 services:
9 mon: 3 daemons, quorum ceph01,ceph02,ceph03
10 mgr: ceph01(active), standbys: ceph02, ceph03
11 osd: 3 osds: 3 up, 3 in
12
13 data:
14 pools: 0 pools, 0 pgs
15 objects: 0 objects, 0 B
16 usage: 3.0 GiB used, 147 GiB / 150 GiB avail
17 pgs:
As you can see, the 3 x 50GB disks have now been added and the total (150 GiB) capacity is available under the data: section.
Now we need to create a ceph storage pool ready for Kubernetes to consume from - the default name of this pool is 'rbd' (if not specified), but it is strongly recommended to name it differently from the default when using for k8s so I've created a storage pool called 'kube' in this example (again running from the mycluster folder on the admin node):
1$ sudo ceph osd pool create kube 30 30
2pool 'kube' created
The two '30's are important - you should review the ceph documentation here for Pool, PG and CRUSH configuration to establish values for PG and PGP appropriate to your environment.
We now associated this pool with the rbd (RADOS block device) application so it is available to be used as a RADOS block device:
1$ sudo ceph osd pool application enable kube rbd
2enabled application 'rbd' on pool 'kube'
Testing Ceph Storage
The easiest way to test our ceph cluster is working correctly and can provide storage is to attempt creating and using a new RADOS Block Device (rbd) volume from our admin node.
Before this will work we need to tune the rbd features map by editing ceph.conf on our client to disable rbd features that aren't available in our Linux kernel (on admin/client node):
1$ echo "rbd_default_features = 7" | sudo tee -a /etc/ceph/ceph.conf
2rbd_default_features = 7
Now we can test creating a volume:
1$ sudo rbd create --size 1G kube/testvol01
Confirm that the volume exists:
1$ sudo rbd ls kube
2testvol01
Get information on our volume:
1$ sudo rbd info kube/testvol01
2rbd image 'testvol01':
3 size 1 GiB in 256 objects
4 order 22 (4 MiB objects)
5 id: 10e96b8b4567
6 block_name_prefix: rbd_data.10e96b8b4567
7 format: 2
8 features: layering, exclusive-lock
9 op_features:
10 flags:
11 create_timestamp: Sun Jan 27 08:50:45 2019
Map the volume to our admin host (which creates the block device /dev/rbd0):
1$ sudo rbd map kube/testvol01
2/dev/rbd0
Now we can create a temporary mount folder, make a filesystem on our volume and mount it to our temporary mount:
1$ sudo mkdir /testmnt
2$ sudo mkfs.xfs /dev/rbd0
3meta-data=/dev/rbd0 isize=512 agcount=9, agsize=31744 blks
4 = sectsz=512 attr=2, projid32bit=1
5 = crc=1 finobt=1, sparse=0
6data = bsize=4096 blocks=262144, imaxpct=25
7 = sunit=1024 swidth=1024 blks
8naming =version 2 bsize=4096 ascii-ci=0 ftype=1
9log =internal log bsize=4096 blocks=2560, version=2
10 = sectsz=512 sunit=8 blks, lazy-count=1
11realtime =none extsz=4096 blocks=0, rtextents=0
12$ sudo mount /dev/rbd0 /testmnt
13$ df -vh
14Filesystem Size Used Avail Use% Mounted on
15udev 1.9G 0 1.9G 0% /dev
16tmpfs 395M 5.7M 389M 2% /run
17/dev/sda1 9.6G 2.2G 7.4G 24% /
18tmpfs 2.0G 0 2.0G 0% /dev/shm
19tmpfs 5.0M 0 5.0M 0% /run/lock
20tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
21/dev/sda15 105M 3.4M 101M 4% /boot/efi
22tmpfs 395M 0 395M 0% /run/user/1001
23/dev/rbd0 1014M 34M 981M 4% /testmnt
We can see our volume has been mounted successfully and can now be used as any other disk.
To tidy up and remove our test volume:
1$ sudo umount /dev/rbd0
2$ sudo rbd unmap kube/testvol01
3$ sudo rbd remove kube/testvol01
4Removing image: 100% complete...done.
5$ sudo rmdir /testmnt
Kubernetes CSE Cluster
Using VMware Container Service Extension (CSE) makes it easy to deploy and configure a base Kubernetes cluster into our vCloud Director platform. I previously wrote a post here with a step-by-step guide to using CSE.
First we need an ssh key pair to provide to the CSE nodes as they are deployed to allow us to access them. You could re-use the cephadmin key-pair created in the previous section, or generate a new set. As I'm using Windows as my client OS I used the puttygen utility included in the PuTTY package to generate a new keypair and save them to a .ssh directory in my home folder.
Check your public key file in a text editor prior to deploying the cluster, if it looks like this: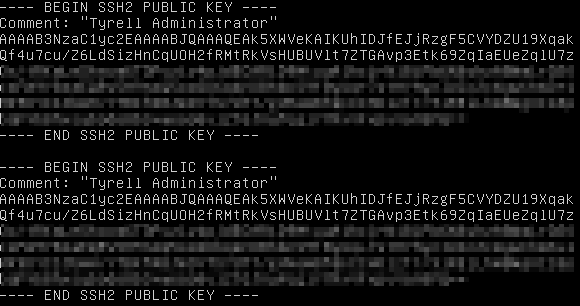

Next we login to vCD using the vcd-cli (see my post linked above if you need to install/configure vcd-cli and the CSE extension):


Now we can see what virtual Datacenters (VDCs) are available to us:
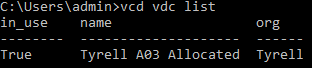
If we had multiple VDCs available, we need to select which one is 'in_use' (active) for deployment of our cluster using vcd vdc use "<VDC Name>". In this case we only have a single VDC and it's already active/in use.
We can get the information of our VDC which will help us fill out the required properties when creating our k8s cluster:
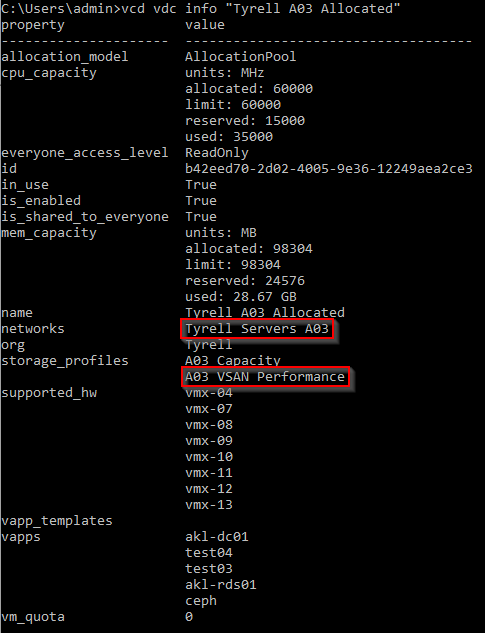
We will be using the 'Tyrell Servers A03' network (where our ceph cluster exists) and the 'A03 VSAN Performance' storage profile for our cluster.
To get the options available when creating a cluster we can see the cluster creation help:
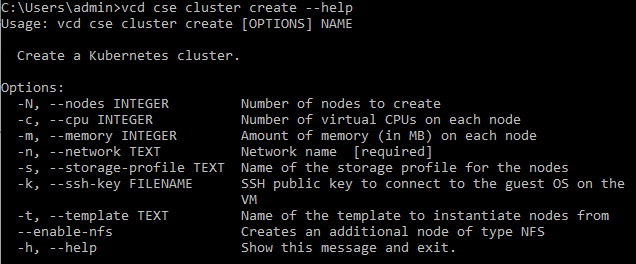
Now we can go ahead and create out Kubernetes cluster with CSE:

Looking in vCloud Director we can see the new vApp and VMs deployed: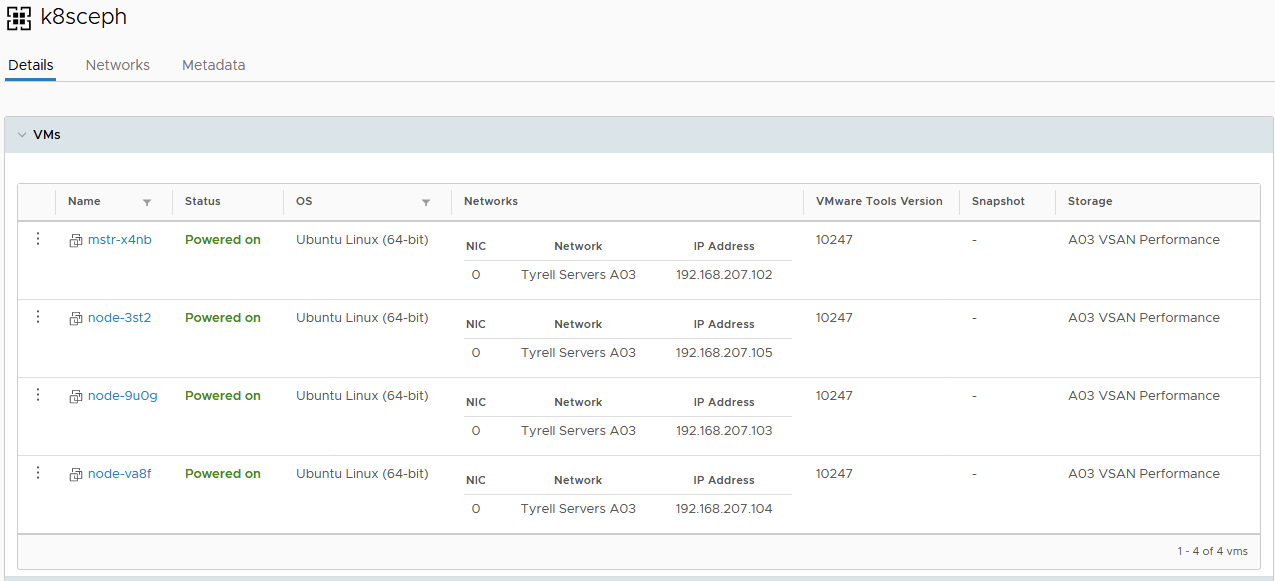
We obtain the kubectl config of our cluster and store this for later use (make the .kube folder first if it doesn't already exist):
1C:\Users\admin>vcd cse cluster config k8sceph > .kube\config
And get the details of our k8s nodes from vcd-cli:
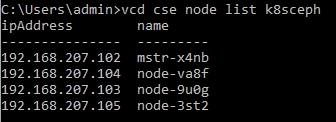
Next we need to update and install the ceph client on each cluster node - run the following on each node (including the master). To do this we can connect via ssh as root using the key pair we specified when creating the cluster.

1# wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
2OK
3# echo deb https://download.ceph.com/debian-mimic/ $(lsb_release -sc) main > /etc/apt/sources.list.d/ceph.list
4# apt-get update
5# apt-get install --install-recommends linux-generic-hwe-16.04 -y
6# apt-get install ceph-common -y
7# reboot
You should now be able to connect from an admin workstation and get the nodes in the kubernetes cluster from kubectl (if you do not already have kubectl installed on your admin workstation, see here for instructions).
If you expand the CSE cluster at any point (add nodes), you will need to repeat this series of commands on each new node in order for it to be able to mount rbd volumes from the ceph cluster.
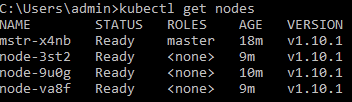
You should also be able to verify that the core kubernetes services are running in your cluster:
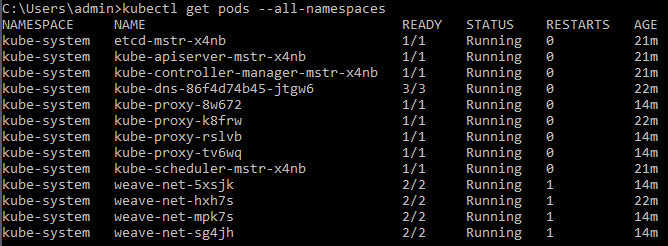
The ceph configuration files from the ceph cluster nodes need to be added to all nodes in the kubernetes cluster. Depending on which ssh keys you have configured for access, you may be able to do this directly from the ceph admin node as follows:
1$ sudo scp /etc/ceph/ceph.* root@192.168.207.102:/etc/ceph/
2$ sudo scp /etc/ceph/ceph.* root@192.168.207.103:/etc/ceph/
3$ sudo scp /etc/ceph/ceph.* root@192.168.207.104:/etc/ceph/
4$ sudo scp /etc/ceph/ceph.* root@192.168.207.105:/etc/ceph/
If not, manually copy the /etc/ceph/ceph.conf and /etc/ceph/ceph.client.admin.keyring files to each of the kubernetes nodes using copy/paste or scp from your admin workstation (copy the files from the ceph admin node to ensure that the rbd_default_features line is included).
To confirm everything is configured correctly, we should now be able to create and mount a test rbd volume on any of the kubernetes nodes as we did for the ceph admin node previously:

1root@mstr-x4nb:~# rbd create --size 1G kube/testvol02
2root@mstr-x4nb:~# rbd ls kube
3root@mstr-x4nb:~# rbd info kube/testvol02
4rbd image 'testvol02':
5 size 1 GiB in 256 objects
6 order 22 (4 MiB objects)
7 id: 10f36b8b4567
8 block_name_prefix: rbd_data.10f36b8b4567
9 format: 2
10 features: layering, exclusive-lock
11 op_features:
12 flags:
13 create_timestamp: Sun Jan 27 21:56:59 2019
14root@mstr-x4nb:~# rbd map kube/testvol02
15/dev/rbd0
16root@mstr-x4nb:~# mkdir /testmnt
17root@mstr-x4nb:~# mkfs.xfs /dev/rbd0
18meta-data=/dev/rbd0 isize=512 agcount=9, agsize=31744 blks
19 = sectsz=512 attr=2, projid32bit=1
20 = crc=1 finobt=1, sparse=0
21data = bsize=4096 blocks=262144, imaxpct=25
22 = sunit=1024 swidth=1024 blks
23naming =version 2 bsize=4096 ascii-ci=0 ftype=1
24log =internal log bsize=4096 blocks=2560, version=2
25 = sectsz=512 sunit=8 blks, lazy-count=1
26realtime =none extsz=4096 blocks=0, rtextents=0
27root@mstr-x4nb:~# mount /dev/rbd0 /testmnt
28root@mstr-x4nb:~# df -vh
29Filesystem Size Used Avail Use% Mounted on
30udev 1.9G 0 1.9G 0% /dev
31tmpfs 395M 5.7M 389M 2% /run
32/dev/sda1 9.6G 4.0G 5.6G 42% /
33tmpfs 2.0G 0 2.0G 0% /dev/shm
34tmpfs 5.0M 0 5.0M 0% /run/lock
35tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
36/dev/sda15 105M 3.4M 101M 4% /boot/efi
37tmpfs 395M 0 395M 0% /run/user/0
38/dev/rbd0 1014M 34M 981M 4% /testmnt
39root@mstr-x4nb:~# umount /testmnt
40root@mstr-x4nb:~# rbd unmap kube/testvol02
41root@mstr-x4nb:~# rmdir /testmnt/
42root@mstr-x4nb:~# rbd remove kube/testvol02
43Removing image: 100% complete...done.
If the rbd map command hangs you may still be running the stock Linux kernel on the kubernetes nodes - make sure you have restarted them.
Now we have a functional ceph storage cluster capable of serving block storage devices over the network, and a Kubernetes cluster configured able to mount rbd devices and use these. In the next section we will configure kubernetes and ceph together with the rbd-provisioner container to enable dynamic persistent storage for pods deployed into our infrastructure.
Putting it all together
Kubernetes secrets
We need to first tell Kubernetes account information to be used to connect to the ceph cluster, to do this we create a 'secret' for the ceph admin user, and also create a client user to be used by k8s provisioning. Working on the kubernetes master node is easiest for this as it has ceph and kubectl already configured from our previous steps:
1# ceph auth get-key client.admin
This will return a key like AQCLY0pcFXBYIxAAhmTCXWwfSIZxJ3WhHnqK/w== which is used in the next command
The '=' sign between -from-literal and key in the following command is not a typo - it actually needs to be like this.
1# kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" \
2--from-literal=key='AQCLY0pcFXBYIxAAhmTCXWwfSIZxJ3WhHnqK/w==' --namespace=kube-system
3secret "ceph-secret" created
We can now create a new ceph user 'kube' and register the secret from this user in kubernetes as 'ceph-secret-kube':
1# ceph auth get-or-create client.kube mon 'allow r' osd 'allow rwx pool=kube'
2[client.kube]
3 key = AQDqZU5c0ahCOBAA7oe+pmoLIXV/8OkX7cNBlw==
4# kubectl create secret generic ceph-secret-kube --type="kubernetes.io/rbd" \
5--from-literal=key='AQDqZU5c0ahCOBAA7oe+pmoLIXV/8OkX7cNBlw==' --namespace=kube-system
6secret "ceph-secret-kube" created
rbd-provisioner
Kubernetes is in the process of moving storage provisioners (such as the rbd one we will be using) out of its main packages and into separate projects and packages. There's also an issue that the kubernetes-controller-manager container no longer has access to an 'rbd' binary in order to be able to connect to a ceph cluster directly. We therefore need to deploy a small 'rbd-provisioner' to act as the go-between from the kubernetes cluster to the ceph storage cluster. This project is available under this link and the steps below show how to obtain get a kubernetes pod running the rbd-provisioner service up and running (again working from the k8s cluster 'master' node):
1# git clone https://github.com/kubernetes-incubator/external-storage
2Cloning into 'external-storage'...
3remote: Enumerating objects: 2, done.
4remote: Counting objects: 100% (2/2), done.
5remote: Compressing objects: 100% (2/2), done.
6remote: Total 63661 (delta 0), reused 1 (delta 0), pack-reused 63659
7Receiving objects: 100% (63661/63661), 113.96 MiB | 8.97 MiB/s, done.
8Resolving deltas: 100% (29075/29075), done.
9Checking connectivity... done.
10# cd external-storage/ceph/rbd/deploy
11# sed -r -i "s/namespace: [^ ]+/namespace: kube-system/g" ./rbac/clusterrolebinding.yaml ./rbac/rolebinding.yaml
12# kubectl -n kube-system apply -f ./rbac
13clusterrole.rbac.authorization.k8s.io "rbd-provisioner" created
14clusterrolebinding.rbac.authorization.k8s.io "rbd-provisioner" created
15deployment.extensions "rbd-provisioner" created
16role.rbac.authorization.k8s.io "rbd-provisioner" created
17rolebinding.rbac.authorization.k8s.io "rbd-provisioner" created
18serviceaccount "rbd-provisioner" created
19# cd
You should now be able to see the 'rbd-provisioner' container starting and then running in kubernetes:
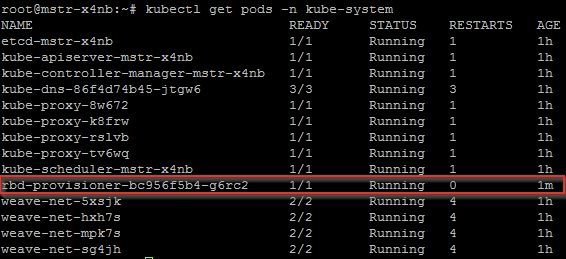
Testing it out
Now we can create our kubernetes Storageclass using this storage ready for a pod to make a persistent volume claim (PVC) against. Create the following as a new file (I've named mine 'rbd-storageclass.yaml'). Change the 'monitors' line to reflect the IP addresses of the 'mon' nodes in your ceph cluster (in our case these are on the ceph01, ceph02 and ceph03 nodes on the IP addresses shown in the file).
1apiVersion: storage.k8s.io/v1
2kind: StorageClass
3metadata:
4 name: rbd
5provisioner: ceph.com/rbd
6parameters:
7 monitors: 192.168.207.201:6789, 192.168.207.202:6789, 192.168.207.203:6789
8 adminId: admin
9 adminSecretName: ceph-secret
10 adminSecretNamespace: kube-system
11 pool: kube
12 userId: kube
13 userSecretName: ceph-secret-kube
14 userSecretNamespace: kube-system
15 imageFormat: "2"
16 imageFeatures: layering
You can then add this StorageClass to kubernetes using:
1# kubectl create -f ./rbd-storageclass.yaml
2storageclass.storage.k8s.io "rbd" created
Next we can create a test PVC and make sure that storage is created in our ceph cluster and assigned to the pod. Create a new file pvc-test.yaml as:
1kind: PersistentVolumeClaim
2apiVersion: v1
3metadata:
4 name: testclaim
5spec:
6 accessModes:
7 - ReadWriteOnce
8 resources:
9 requests:
10 storage: 1Gi
11 storageClassName: rbd
We can now submit the PVC to kubernetes and check it has been successfully created:
1# kubectl create -f ./pvc-test.yaml
2persistentvolumeclaim "testclaim" created
3# kubectl get pvc testclaim
4NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
5testclaim Bound pvc-1e9bdbfd-22a8-11e9-ba77-005056340036 1Gi RWO rbd 21s
6# kubectl describe pvc testclaim
7Name: testclaim
8Namespace: default
9StorageClass: rbd
10Status: Bound
11Volume: pvc-1e9bdbfd-22a8-11e9-ba77-005056340036
12Labels: <none>
13Annotations: pv.kubernetes.io/bind-completed=yes
14 pv.kubernetes.io/bound-by-controller=yes
15 volume.beta.kubernetes.io/storage-provisioner=ceph.com/rbd
16Finalizers: [kubernetes.io/pvc-protection]
17Capacity: 1Gi
18Access Modes: RWO
19Events:
20 Type Reason Age From Message
21 ---- ------ ---- ---- -------
22 Normal ExternalProvisioning 3m persistentvolume-controller waiting for a volume to be created, either by external provisioner "ceph.com/rbd" or manually created by system administrator
23 Normal Provisioning 3m ceph.com/rbd_rbd-provisioner-bc956f5b4-g6rc2_1f37a6c3-22a6-11e9-aa61-7620ed8d4293 External provisioner is provisioning volume for claim "default/testclaim"
24 Normal ProvisioningSucceeded 3m ceph.com/rbd_rbd-provisioner-bc956f5b4-g6rc2_1f37a6c3-22a6-11e9-aa61-7620ed8d4293 Successfully provisioned volume pvc-1e9bdbfd-22a8-11e9-ba77-005056340036
25# rbd list kube
26kubernetes-dynamic-pvc-25e94cb6-22a8-11e9-aa61-7620ed8d4293
27# rbd info kube/kubernetes-dynamic-pvc-25e94cb6-22a8-11e9-aa61-7620ed8d4293
28rbd image 'kubernetes-dynamic-pvc-25e94cb6-22a8-11e9-aa61-7620ed8d4293':
29 size 1 GiB in 256 objects
30 order 22 (4 MiB objects)
31 id: 11616b8b4567
32 block_name_prefix: rbd_data.11616b8b4567
33 format: 2
34 features: layering
35 op_features:
36 flags:
37 create_timestamp: Mon Jan 28 02:55:19 2019
As we can see, our test claim has successfully requested and bound a persistent storage volume from the ceph cluster.
References
| Item | Link |
|---|---|
| Ceph | https://ceph.io/ |
| Docker | https://www.docker.com/ |
| Kubernetes | https://kubernetes.io/ |
| VMware Container Service Extension | https://vmware.github.io/container-service-extension/ |
| VMware vCloud Director for Service Providers | https://docs.vmware.com/en/vCloud-Director/index.html |
Wow, this post ended up way longer than I was anticipating when I started writing it. Hopefully there's something useful for you in amongst all of that.
I'd like to thank members of the vExpert community for their encouragement and advice in getting this post written up and as always, if you have any feedback please leave a comment.
Time-permitting, there will be a followup to this post which details how to deploy containers to this platform using the persistent storage made available, both directly in Kubernetes and using Helm charts. I'd also like to cover some of the more advanced issues using persistent storage in containers raises - in particular backup/recovery and replication/high availability of data stored in this manner.
Jon